
DeepSeek-AI tarafından geliştirilen DeepSeek-R1 ve DeepSeek-R1-Zero modelleri, büyük dil modellerinin (LLM) akıl yürütme yeteneklerini artırmak için pekiştirmeli öğrenme yöntemini kullanmaktadır. (Reinforcement Learning – RL). DeepSeek-R1-Zero, denetimli ince ayar (Supervised Fine-Tuning – SFT) olmadan doğrudan RL ile eğitilmiş bir modeldir ve çeşitli akıl yürütme davranışları sergilemektedir. Ancak, okunabilirlik ve dil karışımı gibi sorunlarla karşılaşır. Bu sorunları çözmek ve performansı daha da artırmak için DeepSeek-R1 modeli geliştirilmiştir. Bu model, soğuk başlangıç verileri ve çok aşamalı bir eğitim süreci içerir. DeepSeek-R1, OpenAI’nin o1-1217 modeliyle karşılaştırılabilir bir performans sergiler.
DeepSeek-R1-Zero ve DeepSeek-R1’in eğitim süreçleri, RL algoritmaları, ödül modellemesi ve performans değerlendirmeleri detaylı bir şekilde açıklanmaktadır. Ayrıca, DeepSeek-R1’den daha küçük modellere akıl yürütme yeteneklerinin aktarılması (distillation) üzerine yapılan çalışmalar da paylaşılmaktadır. Bu küçük modeller, Qwen ve Llama serileri üzerinde eğitilmiş olup, açık kaynak olarak topluma sunulmuştur.
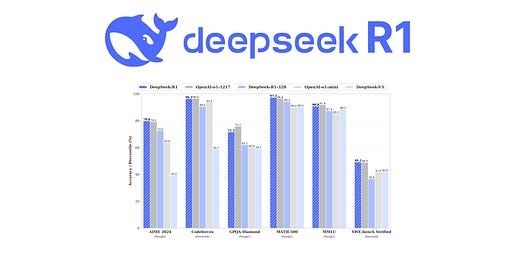
Anahtar Noktalar:
- DeepSeek-R1-Zero: Denetimli ince ayar olmadan doğrudan RL ile eğitilmiş, güçlü akıl yürütme yetenekleri sergileyen bir modeldir
- DeepSeek-R1: Soğuk başlangıç verileri ve çok aşamalı eğitim süreci ile geliştirilmiş, OpenAI’nin o1-1217 modeliyle rekabet edebilen bir modeldir
- Distillation: DeepSeek-R1’den daha küçük modellere akıl yürütme yeteneklerinin aktarılması, bu modellerin performansını önemli ölçüde artırmaktadır.
- Açık Kaynak: DeepSeek-R1-Zero, DeepSeek-R1 ve distile edilmiş modeller (1.5B, 7B, 8B, 14B, 32B, 70B) açık kaynak olarak paylaşılmıştır.
Bu çalışma, LLM’lerin akıl yürütme yeteneklerini artırmak için RL’nin potansiyelini ortaya koymakta ve gelecekteki araştırmalar için önemli bir adım teşkil etmektedir.
Kaynak: 2501.12948